

1. 引言
当我第一次知道 Zookeeper 的功能的时候,我差点就笑出声,这个名字实在起的太妙了。正如 Zookeeper 的网站标语所说的,“因为协调分布式系统就像管理动物园”。
Zookeeper 是一个高性能分布式系统协调服务 (Coordination Service),它采用类似于文件系统的简洁通用的接口,我们可以利用它轻松实现分布式系统同步,配置维护以及服务发现。协调服务因为牵涉到分布式系统的共识机制,实现难度很大。Zookeeper 的出现使得我们在实现分布式系统时不再需要重复实现协调服务,因此,Zookeeper 在一系列耳熟能详的开源服务中被广泛使用,如 Kafka, Hadoop, Hive 和 HBase。
2. Zookeeper 的应用
Zookeeper 会在服务器集群中的多台服务器上同步信息,比如它能存储下列信息:
- 哪个服务器是 Master
- 哪些服务器在线
- 特定服务器在处理什么任务
正因为 Zookeeper 存储了这些信息,客户端可以依靠 Zookeeper 来对服务器集群有一个一致的认识,同时也可以帮助服务器集群本身从部分服务器宕机的事故中恢复状态。
2.1 一致性
从上面的例子中我们可以看到,对于 Zookeeper 存储的信息,我们要求极高的一致性,也只有这些要求高一致性的信息,才适合存储在 Zookeeper 里。 Zookeeper 为了防止它被用在不合适的用途中,默认设置最大的文件尺寸是 1MB。因为通常情况下 Zookeeper 只需要存储一些配置信息,文件尺寸一般会远小于 1MB。
2.2 宕机恢复
- Master 宕机时,Zookeeper 可以检测到它是否还有心跳。如果没有,可以从 Slave 中选出一个来接替,成为 Master。
- Worker 宕机时,Zookeeper 可以检测到它是否还有心跳。如果没有,可以将它承担的工作分配到别的 Worker。
- Zookeeper 可以检测服务器间是不是存在网络问题。如果它发现从不同机器中获得的信息不一致,它可以告知我们的应用。
3. 分布式系统的通用需求
前面的宕机恢复小节涉及了不少在所有分布式系统中都需要解决的问题。这一节我们抛开应用场景,提炼出本质的通用需求。
- 领导选举 (Master Election) - 必要时从一组机器中选出一个领导
- 宕机检测 (Crash Detection) - 机器宕机或者失联时发现及通知
- 集群管理 (Group Management) - 监测集群中有哪些可用的机器
- 元数据存储 (Metadata Store) - 比如管理和分配任务
不难想象,运用这些通用需求作为砖块,我们可以实现 2.2 中的应用场景。
4. 接口设计及数据模型
4.1 设计理念
第三章中提炼出的通用需求正是 Zookeeper 设计者想要实现的。然而,Zookeeper 巧妙之处在于它在这些通用需求中进一步提炼出了共性。
举个例子,如果想要解决领导选举的问题,比较直接的想法是设计诸如 GetLeader 这样的 API。Zookeeper 采用了不同的方案,它提供了一个通用的分布式的文件系统,客户端可以读写这个文件系统。不同于传统的文件系统,Zookeeper 提供了强一致性。这样做一个明显的好处是通用性,Zookeeper 的用户可以利用它构建出符合自己应用需求的领导选举方法。

4.2 接口设计
由于 Zookeeper 提供的分布式文件系统有别于传统的分布式文件系统,在接下去的文章中我们会使用 Zookeeper 的术语做精确表述。
- znode - Zookeeper 里的所谓“文件”的术语
- 核心 API - Create, Delete, exists, setData, getData, getChildren
- 提醒 (Notification) - 客户端可以订阅某个 znode 的提醒,一旦它被修改,客户端会被联系
- Persistent vs Ephemeral znode - 一旦客户端与 Zookeeper 连接超时,Ephemeral znode 就会自动删除。利用这个特性加上提醒,我们可以检测客户端的连接情况并采取行动。
5. 架构
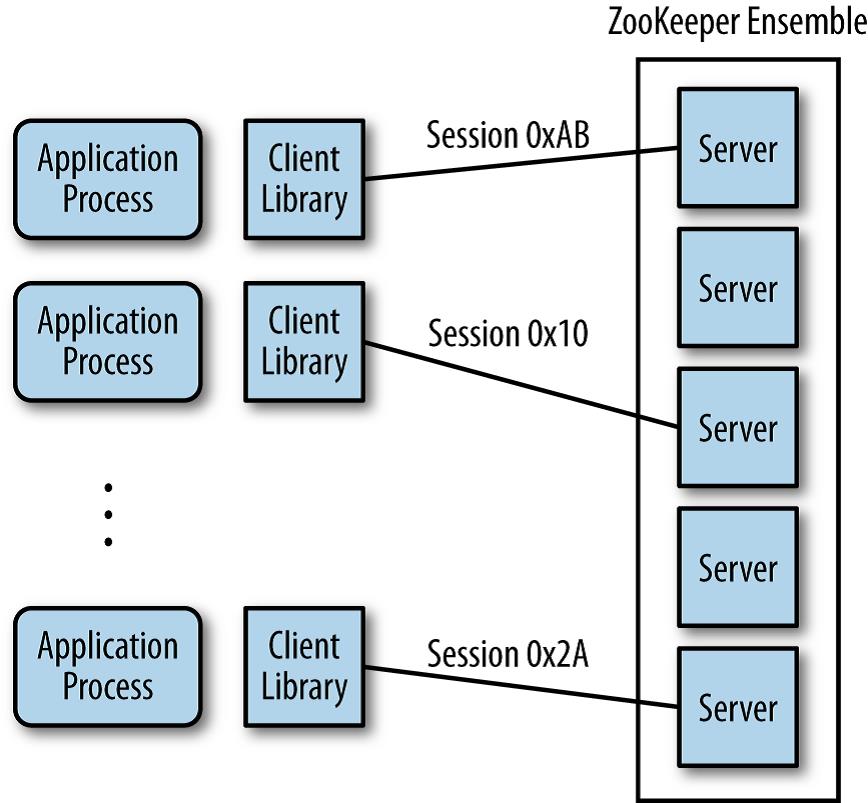
- Zookeeper 服务器端有多台机器(单数台)组成一个集合 (Ensemble)。
- 应用层的每台机器上会含有一个 Zookeeper 客户端库用来和服务器端通讯。
- Zookeeper Ensemble 机器间会互相通信,尽量保持数据的一致性。客户端可以设置,只有在一定数量的服务器完成数据更新后,才确认写入完成。
- Zookeeper Ensemble 需要大于等于一个最小机器数量 (Quorum) 才能正常运行。这个最小机器数量需要大于总机器数的一半,比如在五台机器中最小数量是三台,否则就会有脑裂 (Split Brain) 问题。
- Zookeeper Ensemble 会在所有机器中选出一个 Leader,而其他机器作为 Follower。
6. Zookeeper 实现
6.1 数据流 (Workflow)

Zookeeper 会先将数据写入硬盘,再存储到 in-memory DB。
Leader 和 Follower 都可以接受读请求,只有唯一的 Leader 可以处理写请求,Follower 如果接到写请求会转发给 Leader。
6.2 通讯协议
我们已经知道 Zookeeper 可以在其服务器间保持信息同步,要达到这个目的,Zookeeper 保证对于信息的每一次改动都能保持同步,而改动需要通过消息 (Message) 来传达。
为了下面的内容可以表述的更精确,我们给需要提到的术语做一些解释:
- 消息 (Message) - 一串会给原子 (Atomic) 广播到所有的 Zookeeper 服务器的比特。
- 提案 (Proposal) - 认同的基本单位。提案会被多数的 Zookeeper 服务通过 FIFO 渠道传递的比特来认同。提案可以包含消息,也可以不包含(比如选举领导的提案)
Zookeeper 的通讯协议 (Messaging Protocol) 对于消息的传递提供以下保证:
- 可靠发送 (Reliable Delivery) - 如果消息被一台服务器发送,那么它最终会被所有服务器发送。
- 完整排序 (Total Order) - 如果两条消息按照一定顺序被一台服务器发送,那么它们最终会按照同样的顺序被所有机器发送。所有的已被发送的消息都有先后顺序。
- 因果排序 (Causal Order) - 消息的顺序会按照实际发送顺序来记录。
为了实现以上的保证,Zookeeper 引入了 zxid 来表达顺序。所有提案被提出时会生成一个 zxid 来记录顺序。
zxid 由两部分组成,一个32位的领导数加上一个32位的提案数。领导数代表当前领导是第几个领导,提案数代表当前的提案是该领导治下的第几个提案。
为了能够使得这个 zxid 唯一,我们就必须保证不能有两个领导因为任何原因拥有同样的领导数。下一节中的领导选举机制会提供这个保证。
6.3 领导选举 (Leader Election)
我们正在慢慢触及 Zookeeper 的核心实现方法。Zookeeper 的领导选举算法比较专业,同学们可以作为延伸阅读。本节我们着重介绍数据流。
Zookeeper 领导选举算法有多种,但都满足两个条件:
- 领导见到的 zxid 最大
- 多数服务器认可领导(大概率即可,如果不满足,则重新选举)
领导选举算法选出一个服务器做领导后,Leader 就会等待 Follower 来连接,Follower 也会试图联系 Leader。连接完成后,Leader 要么给 Follower 补发它没收到的提案,要么发送完整的状态。
现在我们可以体会到为什么领导的 zxid 是最大的,因为它见过的提案最多,可以帮助其他机器同步所有提案。但也有例外,如果一个 Follower 在选举完成之后才加入,那么它可能见过有比 Leader 更大的 zxid。此时因为 Leader 已经收到了多数服务器的认可,也就意味着这个更大 zxid 代表的提案没有被多数服务器见过,一定还没有被最终实施,我们可以安全地丢弃它。
6.4 领导激活 (Leader Activation)
在领导选举小节里,服务器们都接收到了领导提出的同步信息。下面是领导激活的步骤:
- 领导会使用新的领导数组成的 zxid 提出一个 NEW_LEADER 提案并开始拒绝接受任何新提案。
- 每个 Follower 都会在检查 zxid 是否正确,提出提案的机器是否是它同步的领导以及跟领导的同步是否完成。只有条件全部满足时会 ACK 领导的提案。
- 如果领导收到多数机器的 ACK,领导实施 NEW_LEADER 提案,完成激活。
- 完成领导激活后,Follower 才会将之前从领导那儿收到的信息实施同步。
如果领导没有收到多数机器的 ACK,那么我们就从头来过,重新选举。
6.5 有领导的消息传递

领导开始正常工作之后事情就简单了。Leader 和 Follower 之间通过二阶段提交 (Two-phase Commit) 来沟通,并保证领导的所有消息传递对于所有 Follower 都是一致并且按照消息接收顺序的。这很容易实现,只要采用先进先出 (FIFO) 的策略,在完成一个 Proposal 只有再开始下一个。领导只有在接收到多数的 ACK 之后才会决定实施 (Commit) 这个提案。Follower 在接收到实施提案的消息时会在本机上将提案实施,包括存储消息本身到硬盘。
7. 参考资料
- Benjamin Reed, Carlos D. Morales. (2012). Apache ZooKeeper
- ZooKeeper: Because Coordinating Distributed Systems is a Zoo
- ZooKeeper Internals
- Frank Kane. (2018). ZooKeeper explained
- Benjamin Reed, Flavio Junqueira. (2013). Zookeeper - Distributed Process Coordination published by O'Reilly